
AI 초보자의 LLM 공부 기록 여섯 번째
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
안녕하세요 클래스메소드의 이수재입니다.
저번 글에 이은 여섯 번째 글입니다.
이 시리즈는 쉽고 빠르게 익히는 실전 LLM이라는 책을 베이스로 공부한 내용을 글로 남기는 것이 목적입니다.
이번 글에서는 책에도 나와있는 몇 가지 예제를 통해 개선되어 가는 것을 확인해보겠습니다.
환경
앞으로는 OpenAI의 API를 이용하여 파인튜닝을 진행해나갈 예정입니다.
코드는 Python으로 작성할 예정입니다.
따라서 제가 작성하는 글은 기본적으로 아래 환경에서 진행됩니다.
- openai : 1.59.7
- Python : 3.13.0
데이터셋
파인튜닝을 위해서는 훈련 및 검증을 위한 데이터셋이 필요합니다.
데이터셋을 제공하는 사이트는 허깅 페이스, 케글 등이 있으며 이외에도 여러 사이트가 있습니다.
한글로 된 데이터셋이 필요한 경우에는 공공데이터포털 등 검색해보면 여러 소스들이 있으니 참고해주세요.
데이터에 대한 모범 사례
파인튜닝을 위한 데이터를 선택할 때 고려해야하는 점이 있습니다.
아래 내용은 책의 본문을 그대로 인용하였습니다.
- 데이터 품질 : 파인튜닝에 사용되는 데이터는 고품질이어야 하며 노이즈가 없어야 하고 대상 도메인이나 작업이 명확해야합니다.
- 데이터 다양성 : 데이터셋이 다양하고 구성되어야 하며, 다양한 시나리오를 포괄하여 모델이 다른 상황에서도 잘 일반화될 수 있어야 합니다.
- 데이터 균형 : 다양한 작업과 도메인 간의 예제 분포를 균형 있게 유지하면 모델의 성능에서 과적합과 편향을 방지할 수 있습니다.
- 데이터 양 : 모델을 파인튜닝하기 위해 필요한 데이터의 총량을 결정합니다. 일반적으로 LLM과 같은 대규모 언어 모델은 다양한 패턴을 효과적으로 파악하고 학습하기 위해 더 광범위한 데이터를 요구하지만 LLM이 유사한 데이터에 대해 사전 훈련되어 있다면 파인 튜닝은 더 적은 데이터셋으로도 충분할 수 있습니다.
Amazon 리뷰 감정 분류
SetFit/amazon_reviews_multi_en 데이터셋을 이용하여 파인튜닝을 통한 개선된 결과를 얻을 수 있는지 확인해보겠습니다.
데이터 셋에서는 여러 제품 카테고리와 여러 언어, 리뷰의 제목과 본문, 별점이 포함되어 있습니다.
이를 바탕으로 OpenAI의 FM을 파인튜닝해보겠습니다.
목표는 리뷰의 제목과 본문의 맥락을 확인하여 리뷰의 등급을 예측하는 것입니다.
이번에는 영어만을 대상으로 파인튜닝을 진행하겠습니다.
데이터셋 만들기
파인튜닝을 진행하기 위해서는 openai에 데이터셋을 업로드 할 필요가 있습니다.
파인튜닝에 사용되는 데이터셋은 25년 1월 기준 chat-formatted data가 필요합니다.
즉, 다음과 같은 데이터가 사용 가능한 데이터셋입니다.
# 아래와 같은 데이터셋은 불가능(prompt-completion)
[{"prompt":"abcd","completion":"abcd"}]
# 아래와 같은 chat 형식의 데이터가 필요
{"messages": [{"role": "system", "content": "You are a chatbot that reads user comments and responds with an expected satisfaction rating between 0 and 5."}, {"role": "user", "content": "This new case for my husband's iPad allows him to work with the iPad as if it were a mini laptop. He loves it."}, {"role": "assistant", "content": "4"}]}
책도 그렇지만 이 글에서 사용하는 데이터셋은 prompt-completion 포맷으로 되어있습니다.
따라서 필요에 따라 chat-formatted 으로 변경해야 합니다.
또한 openAI의 API는 훈련 데이터가 JOSNL 형식일 때 더 좋은 성능을 냅니다.
종합하여 저는 다음과 같은 코드로 형식을 바꾸고 JSONL 파일을 생성하였습니다.
포맷 변경 및 JSONL 파일 저장
from datasets import load_dataset
import pandas as pd
import json
# 아마존 리뷰 데이터셋을 로드
df = load_dataset("SetFit/amazon_reviews_multi_en")
# 데이터셋의 각 서브셋을 pandas DataFrame으로 변환
pre_training_df = pd.DataFrame(df['train'])
pre_validation_df = pd.DataFrame(df['validation'])
pre_test_df = pd.DataFrame(df['test'])
def prepare_df_for_openai(df):
# 텍스트 추출
df['prompt'] = df['text']
# 라벨(점수) 추출
df['completion'] = df['label_text']
# 'prompt' 열을 기준으로 중복 행을 제거
df.drop_duplicates(subset=['prompt'], inplace=True)
# 'prompt' 와 'completion' 열만 포함한 뒤섞이고 필터링된 DataFrame을 반환
df = df[['prompt', 'completion']].sample(len(df))
# prompt-completion 형식의 데이터셋을 chat 형식으로 변경
formatted_data = []
for _, row in df.iterrows():
formatted_data.append({
"messages": [
{"role": "system", "content": "You are a chatbot that reads user comments and responds with an expected satisfaction rating between 0 and 5."},
{"role": "user", "content": row['prompt']},
{"role": "assistant", "content": row['completion']}
]
})
return formatted_data
# 훈련용, 검증용, 테스트용 데이터셋을 생성
training_df = prepare_df_for_openai(pre_training_df)
validation_df = prepare_df_for_openai(pre_validation_df)
test_df = prepare_df_for_openai(pre_test_df)
# 결과물을 jsonl로 저장
with open('amazon_reviews_multi_en_training_set.jsonl', 'w') as f:
for entry in training_df:
f.write(json.dumps(entry) + '\n')
with open('amazon_reviews_multi_en_val_set.jsonl', 'w') as f:
for entry in validation_df:
f.write(json.dumps(entry) + '\n')
with open('amazon_reviews_multi_en_test_set.jsonl', 'w') as f:
for entry in test_df:
f.write(json.dumps(entry) + '\n')
데이터셋 업로드
JSONL 파일이 준비되었다면 이를 업로드합니다.
코드는 다음과 같습니다.
데이터셋 업로드
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("amazon_reviews_multi_en_training_set.jsonl", "rb"),
purpose="fine-tune"
)
client.files.create(
file=open("amazon_reviews_multi_en_val_set.jsonl", "rb"),
purpose="fine-tune"
)
파인튜닝 실행
데이터셋의 업로드가 완료되었다면 파인튜닝을 실행합니다.
업로드가 완료된 데이터셋의 파일id가 필요하며 이는 openai 의 client.files.list() API를 이용하거나 콘솔에서 확인할 수 있습니다.
또한 모델을 지정하는데 저는 가장 저렴한 모델인 gpt-4o-mini를 사용하였습니다.
이 글에서는 에포크를 1번만 실행하였지만 필요에 따라 에포크를 반복하며 훈련을 거듭하는 것도 고려해볼 수 있습니다.
파인 튜닝의 완료까지는 데이터셋의 크기에 따라 달라집니다.
실행하는 코드는 다음과 같습니다.
파인 튜닝 실행
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abcd",
validation_file="file-abcd",
model="gpt-4o-mini-2024-07-18",
suffix="sujae-test",
method={
"type": "supervised",
"supervised": {
"hyperparameters": {
"n_epochs": 1
}
}
}
)
결과 확인하기
파인 튜닝이 완료되었다면 openAI 콘솔에서 해당 훈련의 결과와 플레이 그라운드를 실행할 수 있습니다.
처음 실행한 파인 튜닝은 다음과 같은 결과가 나왔습니다.
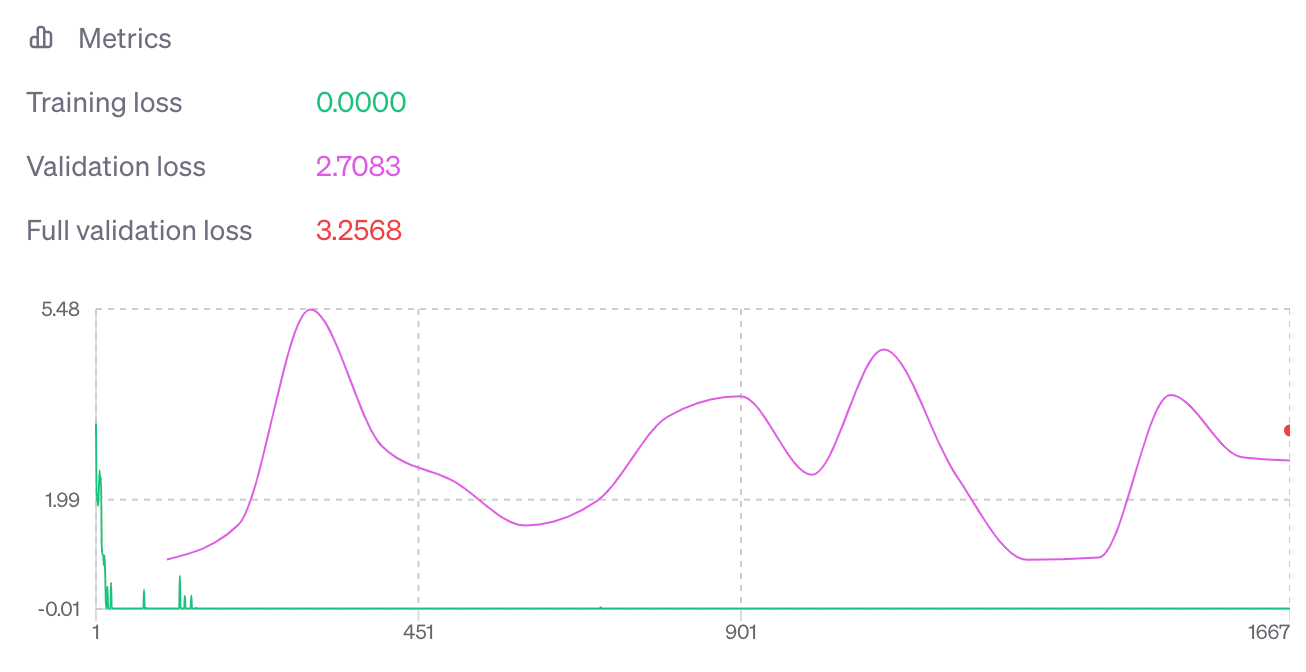
아무래도 과적합이 발생한 것 같았습니다. 실제로 테스트를 해보니 결과가 이상하였습니다.
검토해보니
- 훈련 데이터가 섞이지 않았다(처음부터 끝까지 0점 짜리 데이터였다)
- 10,000 개였던 훈련 데이터의 양이 부족했다
가 문제로 보였습니다.
데이터셋을 수정한 뒤 처음 실행한 훈련의 모델을 사용하여 두 번째 훈련을 진행하였습니다.
두 번째 실행한 훈련의 결과는 다음과 같았습니다.
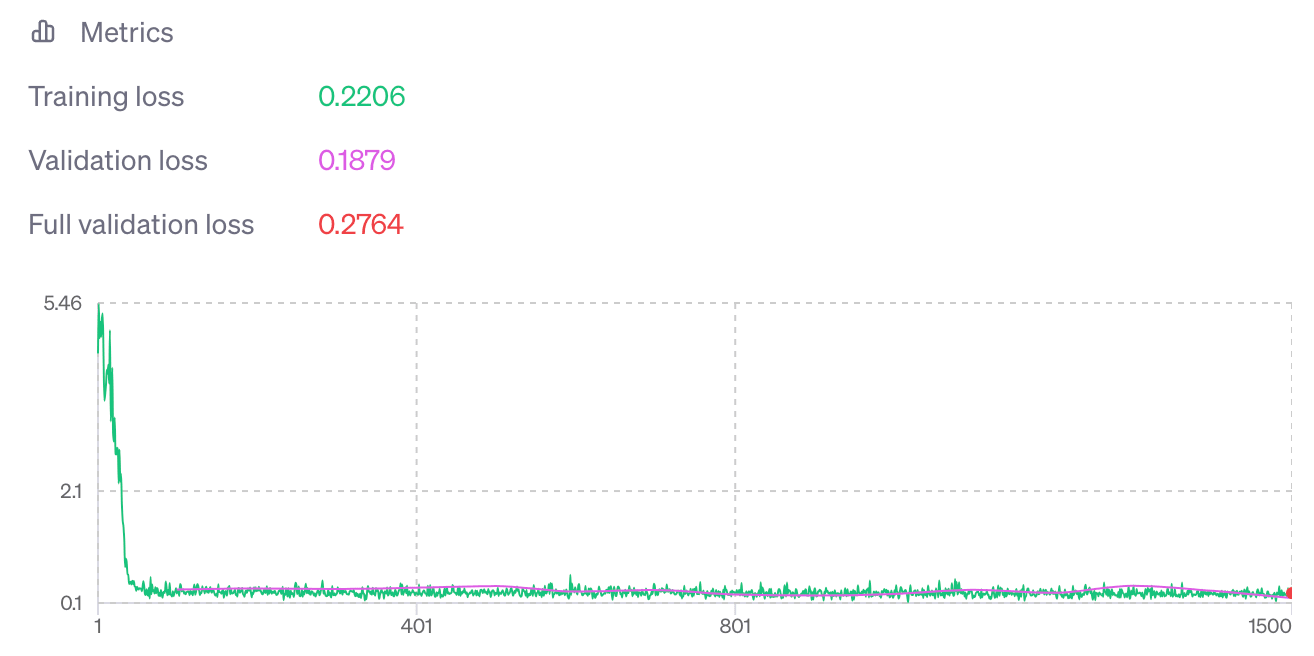
실제로 테스트해보니 결과는 비교적 만족스러웠지만 훈련 손실이 검증 손실보다 높은 점 등 조금 손 볼 부분이 있었습니다.
아무래도 데이터셋의 응답 데이터가 균일하지 못했다는 점이나 데이터셋이 적었던게 문제였을 수도 있겠네요.
마무리
간단한 파인 튜닝을 진행하며 어떤식으로 조작하면 되는지 확인하였습니다.
다음 글부터는 심화된 파인 튜닝에 대하여 알아보겠습니다.
긴 글 읽어주셔서 감사합니다.
오탈자 및 내용 피드백은 must01940 지메일로 보내주시면 감사합니다.










